Comment éviter de faire des notebooks non reproductibles
La reproductibilité du code source est essentielle à la reproductibilité des expériences en général. Or les Jupyter notebooks n’ont pas très bonne presse en matière de reproductibilité. Il y a des raisons objectives à cela, mais on peut aussi prendre certaines précautions pour éviter les problèmes qui font que l’exécutation des notebooks d’un ordinateur à un autre ou avec un intervalle de temps donnent parfois des résultats différents ou bien génèrent des erreurs.
Nommez les Notebooks

Des projets consistants demandent à exécuter plusieurs Jupyter Notebooks, il faut d’un seul coup d’oeil pouvoir déterminer quels sont les notebooks à exécuter dans quel ordre, et pour cela il faut qu’ils soient correctement nommés comme n’importe quel autre fichier. Si on en parle ici c’est que les études faites sur les Jupyter notebooks présents dans Github montrent que ce n’est pas si évident
Méfiez-vous du cache
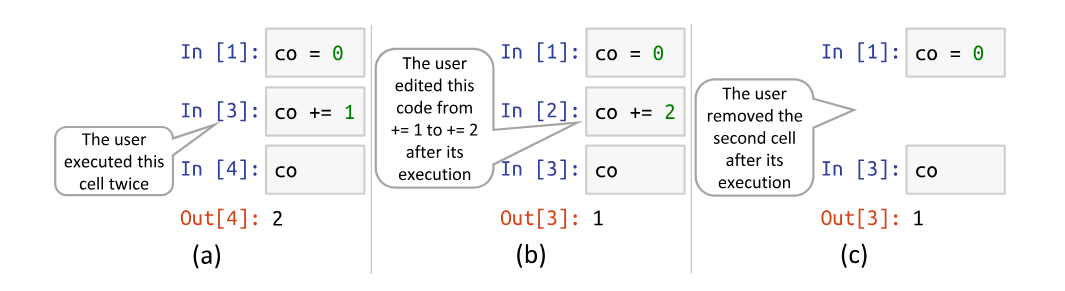
Lorsqu’on supprime une cellule avec une variable, il arrive que la variable et sa valeur reste dans le cache et fausse la valeur obtenue des calculs. De même lorsqu’on change l’ordre des cellules dans un sens puisqu’on revient à la situation initiale après avoir exécuté le code. L’état précédent peut continuer de fausser les résultats. Les Jupyter Notebooks donnent beaucoup de possibilité d’exécuter des cellules une à une et dans l’ordre qu’on souhaite, mais cette liberté à pour contrepartie des opérations maintenues dans le cache (hidden states) et qui faussent les résultats de manière parfois complètement imprévisible 📓1
Identifiez les versions des librairies utilisées
Ecrire pip install <library>est toujours hasardeux, car les versions des librairies dans pip se succèdent à un rythme rapide sans être forcément compatibles avec les versions précédentes. D’où la nécessité d’identifier aussi précisément que possible les versions des librairies utilisées, au moyen d’un fichier requirements.txt. Par exemple, voici celui de notre exercice. Les versions des packages suivent un double signe = 📓2 et3
Utilisez des cellules markdown
Après tout si vous recourez à des notebooks c’est pour faire de la programmation lettrée et expliquez aux autres (et à votre moi ultieur) ce que votre code est censé faire. Sinon pourquoi ne pas écrire directement des scripts ? Pourtant les jupyter notebooks avec très peu de cellules en markdown sont légion et curieusement, ce sont ceux qui sont les plus difficiles à reproduire au bout de quelques mois 📓4
Prévoyez des tests
certes votre recherche est exploratoire, mais il faudra bien qu’elle prenne le chemin d’une publication reproductible et pour cela qu’elle s’appuie sur un code qui comporte une intégration continue et des tests. Prévoyez des données de test et utilisez-les dans votre jupyter notebook pour vérifier que le code donne les résultats escomptés. Ces tests peuvent être effectués à l’intérieur des Jupyter Notebooks au moyen d’applications telles que ipytest (voir tutoriel) 📓2